
Một trong các vấn đề cũng rất được quan tâm đó là hiển thị bộ font đầy đủ tiếng Việt. Không những hiển thị được, việc nhập liệu tiếng việt vào cũng là 1 vấn đề quan trong.
Ngay nay, chuẩn UTF-8 đã rất phổ biến, các trình dịch và phần mềm editer cũng hỗ trợ utf-8 rất nhiều. Vậy nên, ngay từ bây giờ, chúng ta sẽ thiết kế bộ font tiếng việt follow theo chuẩn UTF-8 luôn nhé !
Khả năng của kiểu mã hóa font UTF-8 là độ dài của byte mã hóa không cố định, nó có thể là 1byte, 2byte, 3 byte, 4byte và nhiều hơn nữa nếu muốn, nên nó tiết kiệm được không gian lưu trữ hơn so với unicode 32byte ! Ngoài ra nó cũng tương thích hoàn toàn với bộ mã ASCII
Nói chung, minh cũng không giới thiệu về cách mã hóa UTF-8 làm gì vì nó cũng chả cần thiết lắm. Chúng ta chỉ cần quan tấm tới việc giải mã nó là được rồi.
Ví dụ, chữ À có giá trị tương đường là 0x0000C380. Khi trình dịch biên dịch chữ À, nó sẽ chỉ lưu 2 byte 0xC380 vào bộ nhớ.
Tiếp tục, chữ ắ có giá trị tương đương 0x00E1BAAF. Khi trình dịch biên dịch chữ ắ, nó sẽ lưu 3 byte 0xE1BAAF và bộ nhớ
Byte đầu tiên (cao nhất) chính là cơ sở để ta xác định độ dài của chữ cần giải mã.
- Nếu byte đầu tiên có dạng 0xxx xxxx thì => chữ này chiếm 1 byte thôi
- Nếu byte đầu tiên có dạng 110x xxxx thì => chữ này chiếm 2 byte.
- Nếu byte đầu tiên có dạng 1110 xxxx thì => chữ này đang chiếm 3 byte
- Nếu byte đầu tiên có dạng 1111 0xxx thì => chữ này đang chiếm 4 byte
Mình sẽ đi vào ví dụ ngay:
Trong bộ nhớ của chip có lưu 1 đoạn mã hex như sau:
0x56 0x69 0xe1 0xbb 0x87 0x74 0x20 0x4e 0x61 0x6d 0x20 0x56 0xc3 0xb4 0x20 0xc4 0x90 0xe1 0xbb 0x8b 0x63 0x68 0x20 0x21
Hỏi: Em hãy chuyển đoạn mã hex trên thành văn bản, biết nó được mã hóa UTF-8
- Set byte đầu tiên 0x56(hex) = 0101.0110(bin) => nó có dạng 0xxx.xxx nên nó được mã hóa 1 byte => tra bảng ASCII 0x56= V
- Set byte tiếp theo 0x69(hex) = 0100.0101 (bin) => nó có dạng 0xxx.xxx nên nó được mã hóa 1 byte => tra bảng ASCII 0x69 = i
- Set byte tiếp theo 0xe1(hex) = 1110.0001 (bin) => nó có dạng 1110.xxxx nên nó được mã hóa 3 byte, ta lập tực ghép 2 byte phía sau nó thành 0xE1BB87 => tra bảng UTF-8 => 0xE1BB87 = ệ
- Tiếp tục, bỏ qua 2 byte đã ghép nhảy tới byte 0x74 = 0111.0100 => có dạng 0xxx.xxx nên tra bảng ASCII được chữ t
- ……………………………………. Làm tương tự như trên, kết quả là Việt Nam Vô Địch !
Các bạn thử giải mã hết để hiểu kĩ hơn về cách giải mã utf8 nhé ! Dưới đây là bảng tra UTF-8 cho các kí tự tiếng Việt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
#define UTF8_table_size 144 #define UTF8_char_start1 1 #define UTF8_char_end1 31 #define UTF8_char_start2 127 const uint32_t UTF8_table[UTF8_table_size] = { 0x0000C380, // À 0x0000C381, // Á 0x00E1BAA2, // Ả 0x0000C383, // Ã 0x00E1BAA0, // Ạ 0x0000C482, // Ă 0x00E1BAB0, // Ằ 0x00E1BAAE, // Ắ 0x00E1BAB2, // Ẳ 0x00E1BAB4, // Ẵ 0x00E1BAB6, // Ặ 0x0000C382, // Â 0x00E1BAA6, // Ầ 0x00E1BAA4, // Ấ 0x00E1BAA8, // Ẩ 0x00E1BAAA, // Ẫ 0x00E1BAAC, // Ậ 0x0000C490, // Đ 0x0000C388, // È 0x0000C389, // É 0x00E1BABA, // Ẻ 0x00E1BABC, // Ẽ 0x00E1BAB8, // Ẹ 0x0000C38A, // Ê 0x00E1BB80, // Ề 0x00E1BABE, // Ế 0x00E1BB82, // Ể 0x00E1BB84, // Ễ 0x00E1BB86, // Ệ 0x0000C38C, // Ì 0x0000C38D, // Í 0x00E1BB88, // Ỉ 0x0000C4A8, // Ĩ 0x00E1BB8A, // Ị 0x0000C392, // Ò 0x0000C393, // Ó 0x00E1BB8E, // Ỏ 0x0000C395, // Õ 0x00E1BB8C, // Ọ 0x0000C394, // Ô 0x00E1BB92, // Ồ 0x00E1BB90, // Ố 0x00E1BB94, // Ổ 0x00E1BB96, // Ỗ 0x00E1BB98, // Ộ 0x0000C6A0, // Ơ 0x00E1BB9C, // Ờ 0x00E1BB9A, // Ớ 0x00E1BB9E, // Ở 0x00E1BBA0, // Ỡ 0x00E1BBA2, // Ợ 0x0000C399, // Ù 0x0000C39A, // Ú 0x00E1BBA6, // Ủ 0x0000C5A8, // Ũ 0x00E1BBA4, // Ụ 0x0000C6AF, // Ư 0x00E1BBAA, // Ừ 0x00E1BBA8, // Ứ 0x00E1BBAC, // Ử 0x00E1BBAE, // Ữ 0x00E1BBB0, // Ự 0x00E1BBB2, // Ỳ 0x0000C39D, // Ý 0x00E1BBB6, // Ỷ 0x00E1BBB8, // Ỹ 0x00E1BBB4, // Ỵ 0x0000C3A0, // à 0x0000C3A1, // á 0x00E1BAA3, // ả 0x0000C3A3, // ã 0x00E1BAA1, // ạ 0x0000C483, // ă 0x00E1BAB1, // ằ 0x00E1BAAF, // ắ 0x00E1BAB3, // ẳ 0x00E1BAB5, // ẵ 0x00E1BAB7, // ặ 0x0000C3A2, // â 0x00E1BAA7, // ầ 0x00E1BAA5, // ấ 0x00E1BAA9, // ẩ 0x00E1BAAB, // ẫ 0x00E1BAAD, // ậ 0x0000C491, // đ 0x0000C3A8, // è 0x0000C3A9, // é 0x00E1BABB, // ẻ 0x00E1BABD, // ẽ 0x00E1BAB9, // ẹ 0x0000C3AA, // ê 0x00E1BB81, // ế 0x00E1BABF, // ề 0x00E1BB83, // ể 0x00E1BB85, // ễ 0x00E1BB87, // ệ 0x0000C3AC, // ì 0x0000C3AD, // í 0x00E1BB89, // ỉ 0x0000C4A9, // ĩ 0x00E1BB8B, // ị 0x0000C3B2, // ò 0x0000C3B3, // ó 0x00E1BB8F, // ỏ 0x0000C3B5, // õ 0x00E1BB8D, // ọ 0x0000C3B4, // ô 0x00E1BB93, // ố 0x00E1BB91, // ồ 0x00E1BB95, // ổ 0x00E1BB97, // ỗ 0x00E1BB99, // ộ 0x0000C6A1, // ơ 0x00E1BB9D, // ờ 0x00E1BB9B, // ớ 0x00E1BB9F, // ở 0x00E1BBA1, // ỡ 0x00E1BBA3, // ợ 0x0000C3B9, // ù 0x0000C3BA, // ú 0x00E1BBA7, // ủ 0x0000C5A9, // ũ 0x00E1BBA5, // ụ 0x0000C6B0, // ư 0x00E1BBAB, // ừ 0x00E1BBA9, // ứ 0x00E1BBAD, // ử 0x00E1BBAF, // ữ 0x00E1BBB1, // ự 0x00E1BBB3, // ỳ 0x0000C3BD, // ý 0x00E1BBB7, // ỷ 0x00E1BBB9, // ỹ 0x00E1BBB5, // ỵ } |
Thiết kết bộ mã tiếng việt
Theo bộ mã ASCII chúng ta có các kí tự 0->127 thuộc dải mã này, tuy nhiên từ 0 đến 32 thì là các mã hệ thống, không có khả năng hiển thị nên mình sẽ tận dụng luôn.
Bố cục thứ tự font mình sẽ thiết kế như sau:
Vị trí 0 là NULL nên mình không xài, bắt đầu từ vị trí 1 sẽ lưu chữ À, tiếp tới 2 sẽ là Á … cho tới 31 là chữ Í -> tiếp tới 32 đến 127 là mã ASCII -> tiếp tục từ 127 đến 229 là các kí tự tiếng Việt còn lại -> từ 229 trở đi là các kí tự đặc biệt, icon …
Thứ tự dấu là: Huyền Sắc Hỏi Ngã Nặng
Mình sẽ liệt kế tất cả các kí tự theo thứ tự bắt đầu từ 0 ra như sau:
NULL À Á Ả Ã Ạ Ă Ằ Ắ Ẳ Ẵ Ặ Â Ầ Ấ Ẩ Ẫ Ậ Đ È É Ẻ Ẽ Ẹ Ê Ề Ế Ể Ễ Ệ Ì Í (CÁCH) ! ” # $ % & ‘ ( ) * + , – . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ _ ` a b c d e f g h i j k l m n o p q r s t u v w x y z { | } ~ Ỉ Ĩ Ị Ò Ó Ỏ Õ Ọ Ô Ồ Ố Ổ Ỗ Ộ Ơ Ờ Ớ Ở Ỡ Ợ Ù Ú Ủ Ũ Ụ Ư Ừ Ứ Ử Ữ Ự Ỳ Ý Ỷ Ỹ Ỵ à á ả ã ạ ă ằ ắ ẳ ẵ ặ â ầ ấ ẩ ẫ ậ đ è é ẻ ẽ ẹ ê ề ế ể ễ ệ ì í ỉ ĩ ị ò ó ỏ õ ọ ô ò ố ổ ỗ ộ ơ ờ ớ ở ỡ ợ ù ú ủ ũ ụ ư ừ ứ ử ữ ự ỳ ý ỷ ỹ ỵ ° ❤ 🔊 🕒 ☀ 🌙 ☁ ⏰ 🔟 🔧
Chương trình giải mã UTF-8
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
unsigned char UTF8_GetAddr(unsigned char *utf8_char,unsigned char *char_offset) { *char_offset=1; if((*utf8_char)<UTF8_char_start2) //nếu đây là kí tự trong bản ascii return (*utf8_char); else //nếu đây là kí tự tiếng Việt có đấu { uint32_t utf8_value=0; unsigned char temp = 0xF0 & (*utf8_char); if(temp == 0xC0) //loại utf-8 2 byte { *char_offset=2; utf8_value= (*utf8_char) << 8; utf8_value|=*(utf8_char+1); } else if(temp == 0xE0) //loại utf-8 3 byte { *char_offset = 3; utf8_value= (*utf8_char) << 16; utf8_value|=*(utf8_char+1) << 8; utf8_value|=*(utf8_char+2); } else if(temp == 0xF0) //loại utf-8 4 byte { *char_offset = 4; utf8_value= (*utf8_char) << 24; utf8_value|=*(utf8_char+1) << 16; utf8_value|=*(utf8_char+2) << 8; utf8_value|=*(utf8_char+3); } for(unsigned char i = 0; i < UTF8_table_size; i++) { if(utf8_value == UTF8_table[i]) { if(i<UTF8_char_end1) return i+1; else return i+UTF8_char_start2-UTF8_char_end1; } } return '?'; } } |
Giải thích: đầu tiên mình sẽ check byte đó có nằm trong vùng của ASCII không, nếu đúng thì thoát luôn không cần giải mã nữa vì ta đã làm bộ font tương thích hoàn toàn ASCII rồi ! Ngược lại nếu không phải thì tức là đây là 1 byte bắt đầu của 1 kí tự UTF-8 , công việc là check xem kí tự này chiếm mấy byte bộ nhớ rồi ghép nối các byte rời rạc thành byte lớn kiểu long, sau đó thì tra bảng UTF8_table xem nó trùng với mã nào
Chú ý: Do UTF8_table chúng ta thiết kế bắt dầu từ 0 và liền mạch, còn vị trị thực tế của font lại bắt đầu từ 1 và tới 31 thì ngắt quãng (để nhường cho mã ascii và kí tự NULL) nên lúc return ở dòng 37 và 39 mình có căn chỉnh lại cho khớp !
Thiết kết bộ font tiếng việt
OK. Chúng ta đã đì dai xong bộ mã, giờ đến phần tạo font
Các bạn tạo mã bằng photoshop hoặc pain rồi lưu lại thành file ảnh. Sau đó dùng phần mềm này của để sinh mã hex nhé !
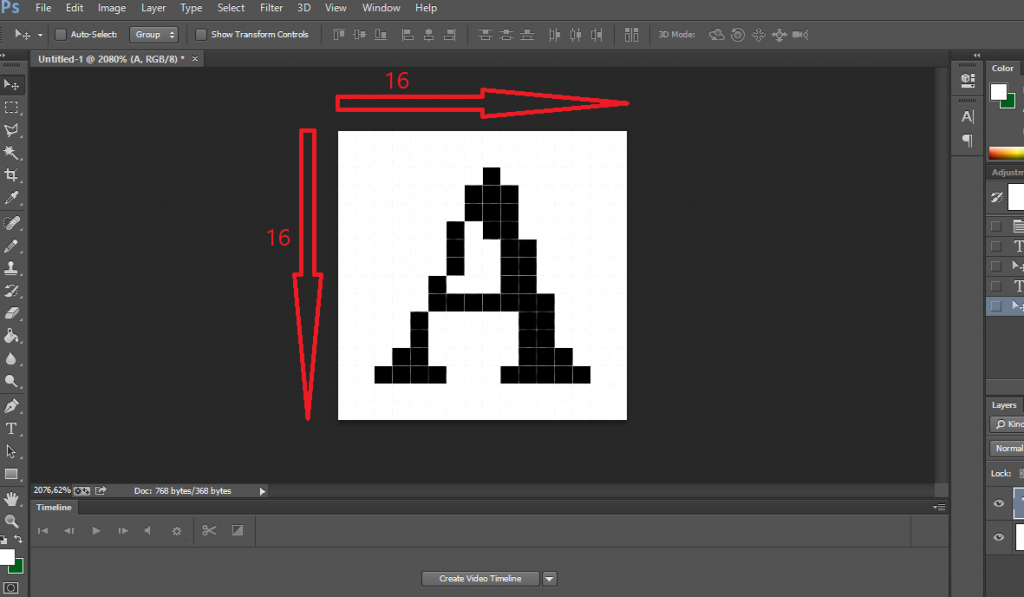
Sau khi có đầy đủ file ảnh của bộ font thì dùng phần mềm để convert sang mã hex nhé !

Các bạn chọn ảnh cần chuyển, tích chọn matrix mono rồi ấn Chuyển đổi là sẽ có mã HEX sinh ra.
Note: Mã hex sinh theo chiều ngang, bit bên trái là bit cao
Còn đây là bộ FONT 16×16 mà mình đã tạo được
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 |
const unsigned char font16[] = { 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //NULL 0x00,0x00,0x00,0x00,0x08,0x00,0x04,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00, //AF 1 0x00,0x00,0x00,0x00,0x02,0x00,0x04,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00, //AS 2 0x00,0x00,0x00,0x00,0x0C,0x00,0x04,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00, //AR 3 0x00,0x00,0x00,0x00,0x0D,0x00,0x12,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00, //AX 4 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x04,0x00, //AJ 5 0x00,0x00,0x00,0x00,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AW 6 0x01,0x00,0x00,0x80,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AWF 7 0x00,0x40,0x00,0x80,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AWS 8 0x01,0x80,0x00,0x80,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AWR 9 0x00,0x50,0x00,0xA0,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AWX 10 0x00,0x00,0x00,0x00,0x12,0x00,0x0C,0x00,0x00,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x04,0x00,//AWJ 11 0x00,0x00,0x00,0x00,0x00,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AA 12 0x00,0x00,0x02,0x00,0x01,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AAF 13 0x00,0x00,0x00,0x80,0x01,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AAS 14 0x00,0x00,0x03,0x00,0x01,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AAR 15 0x01,0xA0,0x02,0x40,0x00,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//AAX 16 0x00,0x00,0x00,0x00,0x00,0x00,0x0C,0x00,0x12,0x00,0x0C,0x00,0x16,0x00,0x16,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x04,0x00,//AAJ 17 0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0x00,0x63,0x00,0x61,0x80,0x60,0xC0,0x60,0xC0, 0xF0,0xC0,0xF0,0xC0,0x60,0xC0,0x61,0x80,0x63,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,//DD 18 0x10,0x00,0x08,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EF 21 0x04,0x00,0x08,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//ES 20 0x1C,0x00,0x04,0x00,0x08,0x00,0xFF,0x80,0x31,0x80,0x30,0x80,0x32,0x00,0x32,0x00, 0x3E,0x00,0x32,0x00,0x32,0x00,0x30,0x80,0x31,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//ER 21 0x1A,0x00,0x24,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EX 22 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x08,0x00,//EJ 23 0x0C,0x00,0x12,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EE 24 0x0C,0x80,0x12,0x40,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EEF 25 0x0C,0x40,0x12,0x80,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EES 26 0x0C,0xC0,0x12,0x40,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//EER 27 0x1d,0x40,0x22,0x80,0x00,0x00,0xff,0x80,0x31,0x80,0x30,0x80,0x32,0x00,0x32,0x00, 0x3e,0x00,0x32,0x00,0x32,0x00,0x30,0x80,0x31,0x80,0xff,0x80,0x00,0x00,0x00,0x00, //EEX 28 0x0C,0x00,0x12,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x04,0x00, //EEJ 29 0x20,0x00,0x10,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//IF 30 0x08,0x00,0x10,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//IS 31 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //space 0x00,0x00,0x00,0x00,0x00,0x00,0x18,0x00,0x3C,0x00,0x3C,0x00,0x3C,0x00,0x3C,0x00, 0x18,0x00,0x18,0x00,0x18,0x00,0x00,0x00,0x18,0x00,0x18,0x00,0x00,0x00,0x00,0x00,//! 9 0x00,0x00,0x00,0x00,0x00,0x00,0x66,0x00,0x66,0x00,0x66,0x00,0x66,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,//" 9 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //space big 0x00,0x00,0x00,0x00,0x08,0x00,0x3E,0x00,0x6B,0x00,0x69,0x00,0x68,0x00,0x38,0x00, 0x1C,0x00,0x0E,0x00,0x0F,0x00,0x4B,0x00,0x6B,0x00,0x3E,0x00,0x08,0x00,0x00,0x00,//$ 0x00,0x00,0x00,0x00,0x60,0x80,0x91,0x00,0x92,0x00,0x64,0x00,0x04,0x00,0x08,0x00, 0x18,0x00,0x13,0x00,0x24,0x80,0x44,0x80,0x83,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //% 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x1C,0x00,0x32,0x00,0x32,0x00, 0x34,0x00,0x5B,0x80,0xD9,0x00,0xCE,0x00,0xE6,0x80,0x7B,0x00,0x00,0x00,0x00,0x00,//& 10 0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,//' 4 0x00,0x00,0x00,0x00,0x08,0x00,0x10,0x00,0x30,0x00,0x60,0x00,0x60,0x00,0x60,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x30,0x00,0x10,0x00,0x08,0x00,0x00,0x00,0x00,0x00,//( 7 0x00,0x00,0x00,0x00,0x40,0x00,0x20,0x00,0x30,0x00,0x18,0x00,0x18,0x00,0x18,0x00, 0x18,0x00,0x18,0x00,0x18,0x00,0x30,0x00,0x20,0x00,0x40,0x00,0x00,0x00,0x00,0x00,//$ ) 7 0x00,0x00,0x00,0x00,0x00,0x00,0x10,0x00,0x10,0x00,0x7C,0x00,0x10,0x00,0x28,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,//* 8 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //space 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x20,0x00,0x40,0x00,0x00,0x00,//, 4 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x3C,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,//- 7 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x00,0x00,0x00,0x00,//. 4 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x04,0x00,0x08,0x00,0x10,0x00,0x10,0x00, 0x10,0x00,0x20,0x00,0x20,0x00,0x20,0x00,0x40,0x00,0x40,0x00,0x00,0x00,0x00,0x00,// / 8 0x00,0x00,0x00,0x00,0x00,0x00,0x3C,0x00,0x66,0x00,0xC3,0x00,0xC3,0x00,0xC3,0x00, 0xC3,0x00,0xC3,0x00,0xC3,0x00,0xC3,0x00,0x66,0x00,0x3C,0x00,0x00,0x00,0x00,0x00,//0 9 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0xF0,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//1 7 0x00,0x00,0x00,0x00,0x00,0x00,0x3C,0x00,0x7E,0x00,0xCE,0x00,0x06,0x00,0x06,0x00, 0x04,0x00,0x08,0x00,0x10,0x00,0x21,0x00,0x7E,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,//2 9 0x00,0x00,0x00,0x00,0x00,0x00,0x3C,0x00,0x7E,0x00,0xC6,0x00,0x04,0x00,0x1C,0x00, 0x0E,0x00,0x07,0x00,0x03,0x00,0xC3,0x00,0xE2,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//3 9 0x00,0x00,0x00,0x00,0x00,0x00,0x02,0x00,0x06,0x00,0x0E,0x00,0x16,0x00,0x26,0x00, 0x46,0x00,0xFF,0x00,0xFF,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x00,0x00,0x00,0x00,//4 9 0x00,0x00,0x00,0x00,0x00,0x00,0x3F,0x00,0x7E,0x00,0x40,0x00,0x78,0x00,0xFE,0x00, 0x0F,0x00,0x03,0x00,0x01,0x00,0x01,0x00,0xE2,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//5 9 0x00,0x00,0x00,0x00,0x00,0x00,0x07,0x00,0x1C,0x00,0x30,0x00,0x70,0x00,0xFC,0x00, 0xE6,0x00,0xC3,0x00,0xC3,0x00,0xC3,0x00,0x66,0x00,0x3C,0x00,0x00,0x00,0x00,0x00,//6 9 0x00,0x00,0x00,0x00,0x00,0x00,0x7E,0x00,0xFE,0x00,0x82,0x00,0x04,0x00,0x04,0x00, 0x04,0x00,0x08,0x00,0x08,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x00,0x00,0x00,0x00,//7 8 0x00,0x00,0x00,0x00,0x00,0x00,0x3E,0x00,0xC7,0x00,0xC3,0x00,0xE3,0x00,0x7E,0x00, 0x3C,0x00,0x4E,0x00,0xC3,0x00,0xC3,0x00,0xE2,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//8 9 0x00,0x00,0x00,0x00,0x00,0x00,0x3C,0x00,0x66,0x00,0xC3,0x00,0xC3,0x00,0xC3,0x00, 0x63,0x00,0x3F,0x00,0x06,0x00,0x0C,0x00,0x38,0x00,0xE0,0x00,0x00,0x00,0x00,0x00,//9 9 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x00,0x00,0x00,0x00,//: 5 0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x60,0x00,0x60,0x00,0x20,0x00,0x20,0x00,0x40,0x00,0x00,0x00,0x00,0x00,//; 5 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x80,0x03,0x00,0x1C,0x00,0x60,0x00, 0x80,0x00,0x60,0x00,0x1C,0x00,0x03,0x00,0x00,0x80,0x00,0x00,0x00,0x00,0x00,0x00,//< 10 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x80, 0x00,0x00,0x00,0x00,0xFF,0x80,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,// = 10 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x80,0x00,0x60,0x00,0x1C,0x00,0x03,0x00, 0x00,0x80,0x03,0x00,0x1C,0x00,0x60,0x00,0x80,0x00,0x00,0x00,0x00,0x00,0x00,0x00,//> 10 0x00,0x00,0x00,0x00,0x00,0x00,0x7C,0x00,0xCE,0x00,0xC6,0x00,0x06,0x00,0x04,0x00, 0x08,0x00,0x10,0x00,0x10,0x00,0x00,0x00,0x30,0x00,0x30,0x00,0x00,0x00,0x00,0x00,//? 8 0x00,0x00,0x0F,0xE0,0x10,0x10,0x20,0x08,0x47,0x64,0x8C,0xC4,0x98,0xC4,0x98,0xC4, 0x99,0x84,0x99,0x88,0x9B,0x90,0x8C,0xE2,0x40,0x04,0x20,0x08,0x10,0x10,0x0F,0xE0,//@ 16 0x00,0x00,0x00,0x00,0x00,0x00,0x04,0x00,0x0C,0x00,0x0E,0x00,0x16,0x00,0x17,0x00, 0x13,0x00,0x23,0x00,0x3F,0x80,0x21,0x80,0x40,0xC0,0xF3,0xE0,0x00,0x00,0x00,0x00,//A 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x00,0x61,0x80,0x60,0xC0,0x60,0xC0,0x61,0x80, 0x7F,0x00,0x61,0x80,0x60,0xC0,0x60,0xC0,0x61,0x80,0xFF,0x00,0x00,0x00,0x00,0x00,//B 0x00,0x00,0x00,0x00,0x00,0x00,0x1E,0x40,0x31,0xC0,0x60,0xC0,0xC0,0x40,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0x60,0x40,0x30,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//C 0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0x00,0x63,0x00,0x61,0x80,0x60,0xC0,0x60,0xC0, 0x60,0xC0,0x60,0xC0,0x60,0xC0,0x61,0x80,0x63,0x00,0xFE,0x00,0x00,0x00,0x00,0x00,//D 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//E 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x80,0x61,0x80,0x60,0x80,0x64,0x00,0x64,0x00, 0x7C,0x00,0x64,0x00,0x64,0x00,0x60,0x00,0x60,0x00,0xF8,0x00,0x00,0x00,0x00,0x00,//F 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x20,0x30,0xE0,0x60,0x60,0xC0,0x20,0xC0,0x00, 0xC0,0x00,0xC1,0xE0,0xC0,0x60,0x60,0x60,0x30,0x60,0x1F,0x80,0x00,0x00,0x00,0x00,//G 0x00,0x00,0x00,0x00,0x00,0x00,0xFB,0xE0,0x60,0xC0,0x60,0xC0,0x60,0xC0,0x60,0xC0, 0x7F,0xC0,0x60,0xC0,0x60,0xC0,0x60,0xC0,0x60,0xC0,0xFB,0xE0,0x00,0x00,0x00,0x00,//H 0x00,0x00,0x00,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//I 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x80,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00, 0x06,0x00,0x06,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//J 0x00,0x00,0x00,0x00,0x00,0x00,0xF9,0xE0,0x60,0x80,0x61,0x00,0x66,0x00,0x68,0x00, 0x78,0x00,0x6C,0x00,0x66,0x00,0x63,0x00,0x61,0x80,0xFB,0xE0,0x00,0x00,0x00,0x00,//K 0x00,0x00,0x00,0x00,0x00,0x00,0xF8,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x80,0x61,0x80,0xFF,0x80,0x00,0x00,0x00,0x00,//L 0x00,0x00,0x00,0x00,0x00,0x00,0xF0,0x3C,0x70,0x38,0x58,0x58,0x58,0x58,0x58,0x98, 0x4C,0x98,0x4C,0x98,0x4D,0x18,0x47,0x18,0x46,0x18,0xF2,0x7C,0x00,0x00,0x00,0x00,//M 0x00,0x00,0x00,0x00,0x00,0x00,0xF9,0xF0,0x38,0x40,0x2C,0x40,0x26,0x40,0x26,0x40, 0x23,0x40,0x21,0xC0,0x21,0xC0,0x20,0xC0,0x20,0x40,0xF8,0x40,0x00,0x00,0x00,0x00,//N 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//O 0x00,0x00,0x00,0x00,0x00,0x00,0xFE,0x00,0x63,0x00,0x61,0x80,0x61,0x80,0x63,0x00, 0x7E,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0xF8,0x00,0x00,0x00,0x00,0x00,//P 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x06,0x00,0x01,0xE0,//Q 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0x00,0x61,0x80,0x60,0xC0,0x60,0xC0,0x61,0x80, 0x7E,0x00,0x66,0x00,0x63,0x00,0x63,0x00,0x61,0x80,0xF9,0xE0,0x00,0x00,0x00,0x00,//R 0x00,0x00,0x00,0x00,0x00,0x00,0x7A,0x00,0xC6,0x00,0xC2,0x00,0xE2,0x00,0x70,0x00, 0x3C,0x00,0x0E,0x00,0x86,0x00,0x86,0x00,0xC6,0x00,0xBC,0x00,0x00,0x00,0x00,0x00,//S 0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xC0,0x8C,0x40,0x8C,0x40,0x0C,0x00,0x0C,0x00, 0x0C,0x00,0x0C,0x00,0x0C,0x00,0x0C,0x00,0x0C,0x00,0x3F,0x00,0x00,0x00,0x00,0x00,//T 0x00,0x00,0x00,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//U 0x00,0x00,0x00,0x00,0x00,0x00,0xF8,0xF0,0x30,0x40,0x30,0x40,0x18,0x80,0x18,0x80, 0x19,0x00,0x0D,0x00,0x0D,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x00,0x00,0x00,0x00,//V 0x00,0x00,0x00,0x00,0x00,0x00,0xF7,0xC7,0x61,0x82,0x61,0xC2,0x32,0xC4,0x32,0xC4, 0x32,0x68,0x1A,0x68,0x1C,0x68,0x0C,0x30,0x0C,0x30,0x0C,0x30,0x00,0x00,0x00,0x00,//W 0x00,0x00,0x00,0x00,0x00,0x00,0xF8,0xF0,0x70,0x40,0x38,0x80,0x19,0x00,0x0E,0x00, 0x0E,0x00,0x06,0x00,0x0F,0x00,0x13,0x80,0x21,0x80,0xF3,0xE0,0x00,0x00,0x00,0x00,//X 0x00,0x00,0x00,0x00,0x00,0x00,0xF9,0xE0,0x70,0x40,0x38,0x80,0x18,0x80,0x1D,0x00, 0x0E,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x00,0x00,//Y 0x00,0x00,0x00,0x00,0x00,0x00,0x7F,0xC0,0x61,0x80,0x43,0x00,0x47,0x00,0x06,0x00, 0x0C,0x00,0x18,0x00,0x38,0x40,0x30,0x40,0x60,0xC0,0xFF,0xC0,0x00,0x00,0x00,0x00,//Z 0x00,0x00,0x7f,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00, 0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x40,0x00,0x7f,0x00,0x00,0x00, //[ 0x00,0x00,0x00,0x00,0x80,0x00,0x40,0x00,0x20,0x00,0x10,0x00,0x10,0x00,0x08,0x00, 0x08,0x00,0x04,0x00,0x04,0x00,0x02,0x00,0x02,0x00,0x01,0x00,0x00,0x00,0x00,0x00, // 0x00,0x00,0x7f,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00, 0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x00,0x7f,0x00,0x00,0x00, //] 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x7f,0x00,0x00,0x00, //] 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x7f,0x00,0x00,0x00, //_ 0x00,0x00,0x40,0x00,0x20,0x00,0x10,0x00,0x08,0x00,0x04,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //` 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//a 0x00,0x00,0x00,0x00,0x00,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x6C,0x00,0x76,0x00, 0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x66,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//b 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x38,0x00,0x4C,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x64,0x00,0x38,0x00,0x00,0x00,0x00,0x00,//c 0x00,0x00,0x00,0x00,0x00,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x36,0x00,0x6E,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x6F,0x00,0x36,0x00,0x00,0x00,0x00,0x00,//d 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//e 0x00,0x00,0x00,0x00,0x00,0x00,0x3C,0x00,0x6C,0x00,0x60,0x00,0xF0,0x00,0x60,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0xF0,0x00,0x00,0x00,0x00,0x00,//f 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x3F,0x00,0x46,0x00, 0xC6,0x00,0xC6,0x00,0xC4,0x00,0x78,0x00,0x40,0x00,0xFE,0x00,0xFF,0x00,0x81,0x00,//g 0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xDC,0x00,0xE6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xEF,0x00,0x00,0x00,0x00,0x00,//h 0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,//i 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x30,0x00,0x00,0x00,0x70,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xB0,0x00,0x60,0x00,//j 0x00,0x00,0x00,0x00,0x00,0x00,0xE0,0x00,0x60,0x00,0x60,0x00,0x67,0x00,0x64,0x00, 0x68,0x00,0x78,0x00,0x6C,0x00,0x66,0x00,0x63,0x00,0xF7,0x80,0x00,0x00,0x00,0x00,//k 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xE0,0x00,0x60,0x00,0x60,0x00,0x60,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//l 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xEE,0x70,0x73,0x98, 0x63,0x18,0x63,0x18,0x63,0x18,0x63,0x18,0x63,0x18,0xF3,0x9C,0x00,0x00,0x00,0x00,//m 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xEE,0x00,0x73,0x00, 0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0xF7,0x80,0x00,0x00,0x00,0x00,//n 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//o 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xD8,0x00,0xEC,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xEC,0x00,0xD8,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,//p 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x3A,0x00,0x66,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0x6E,0x00,0x36,0x00,0x06,0x00,0x06,0x00,0x06,0x00,//q 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xEC,0x00,0x74,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0xF0,0x00,0x00,0x00,0x00,0x00,//r 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x78,0x00,0xC8,0x00, 0xC0,0x00,0xF0,0x00,0x78,0x00,0x18,0x00,0x98,0x00,0xF0,0x00,0x00,0x00,0x00,0x00,//s 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x60,0x00,0xF8,0x00,0x60,0x00, 0x60,0x00,0x60,0x00,0x60,0x00,0x60,0x00,0x64,0x00,0x38,0x00,0x00,0x00,0x00,0x00,//t 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//u 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xF7,0x00,0x62,0x00, 0x72,0x00,0x34,0x00,0x34,0x00,0x38,0x00,0x18,0x00,0x18,0x00,0x00,0x00,0x00,0x00,//v 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xEF,0x60,0xC6,0x20, 0x6B,0x40,0x6B,0x40,0x6B,0x40,0x31,0x80,0x31,0x80,0x31,0x80,0x00,0x00,0x00,0x00,//w 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xF7,0x00,0x62,0x00, 0x34,0x00,0x38,0x00,0x1C,0x00,0x2C,0x00,0x46,0x00,0xEF,0x00,0x00,0x00,0x00,0x00,//x 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x20,0x00,//y 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFC,0x00,0x98,0x00, 0x18,0x00,0x30,0x00,0x30,0x00,0x64,0x00,0x6C,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,// z 0x00,0x00,0x0c,0x00,0x10,0x00,0x20,0x00,0x20,0x00,0x20,0x00,0x20,0x00,0xe0,0x00, 0xe0,0x00,0x20,0x00,0x20,0x00,0x20,0x00,0x20,0x00,0x10,0x00,0x0c,0x00,0x00,0x00, //{ 0x00,0x00,0x00,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00, 0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x00,0x00,0x00,0x00, //| 0x00,0x00,0xc0,0x00,0x20,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x18,0x00, 0x18,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x10,0x00,0x20,0x00,0xc0,0x00,0x00,0x00, //{ 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x64,0x00,0x94,0x00,0x98,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, //~ 0x30,0x00,0x10,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//IR 127 0x34,0x00,0x48,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x00,0x00,//IX 128 0x00,0x00,0x00,0x00,0x00,0x00,0xFC,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00, 0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0x30,0x00,0xFC,0x00,0x00,0x00,0x30,0x00,//IJ 129 0x08,0x00,0x04,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OF 130 0x02,0x00,0x04,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OS 131 0x0C,0x00,0x04,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OR 132 0x0D,0x00,0x12,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OX 133 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x04,0x00,//OJ 134 0x0E,0x00,0x11,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OO 135 0x0E,0x40,0x11,0x20,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OOF 136 0x0E,0x20,0x11,0x40,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OOS 137 0x0E,0x60,0x11,0x20,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OOR 138 0x0E,0xA0,0x11,0x50,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OOX 139 0x0E,0x00,0x11,0x00,0x00,0x00,0x1F,0x00,0x31,0x80,0x60,0xC0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x04,0x00,//OOJ 140 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OW 141 0x08,0x00,0x04,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OWF 142 0x02,0x00,0x04,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OWS 143 0x0C,0x00,0x04,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OWR 144 0x0D,0x00,0x12,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x00,0x00,//OWX 145 0x00,0x00,0x00,0x00,0x00,0x00,0x1F,0x30,0x31,0x90,0x60,0xE0,0xC0,0x60,0xC0,0x60, 0xC0,0x60,0xC0,0x60,0xC0,0x60,0x60,0xC0,0x31,0x80,0x1F,0x00,0x00,0x00,0x04,0x00,//OWJ 146 0x08,0x00,0x04,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UF 147 0x02,0x00,0x04,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//US 148 0x0C,0x00,0x04,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UR 149 0x0D,0x00,0x12,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UX 150 0x00,0x00,0x00,0x00,0x00,0x00,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x04,0x00,//UJ 151 0x00,0x00,0x00,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UW 152 0x08,0x00,0x04,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UWF 153 0x02,0x00,0x04,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UWS 154 0x0C,0x00,0x04,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UWR 155 0x0D,0x00,0x12,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x00,0x00,//UWX 156 0x0D,0x00,0x12,0x60,0x00,0x20,0xFB,0xC0,0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80, 0x60,0x80,0x60,0x80,0x60,0x80,0x60,0x80,0x31,0x00,0x1E,0x00,0x00,0x00,0x04,0x00,//UWJ 157 0x04,0x00,0x02,0x00,0x00,0x00,0xF9,0xF0,0x70,0x60,0x38,0x40,0x18,0x80,0x0D,0x00, 0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x00,0x00,//YF 159 0x01,0x00,0x02,0x00,0x00,0x00,0xF9,0xF0,0x70,0x60,0x38,0x40,0x18,0x80,0x0D,0x00, 0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x00,0x00,//YS 160 0x06,0x00,0x02,0x00,0x00,0x00,0xF9,0xF0,0x70,0x60,0x38,0x40,0x18,0x80,0x0D,0x00, 0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x00,0x00,//YR 160 0x06,0x80,0x09,0x00,0x00,0x00,0xF9,0xF0,0x70,0x60,0x38,0x40,0x18,0x80,0x0D,0x00, 0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x00,0x00,//YX 161 0x00,0x00,0x00,0x00,0x00,0x00,0xF9,0xF0,0x70,0x60,0x38,0x40,0x18,0x80,0x0D,0x00, 0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x06,0x00,0x1F,0x80,0x00,0x00,0x06,0x00,//YJ 162 0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//af 163 0x00,0x00,0x00,0x00,0x00,0x00,0x08,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//as 164 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//ar 165 0x00,0x00,0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//ax 166 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x10,0x00,//aj 167 0x00,0x00,0x00,0x00,0x00,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aw 168 0x00,0x00,0x20,0x00,0x10,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//awf 169 0x00,0x00,0x08,0x00,0x10,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aws 170 0x00,0x00,0x18,0x00,0x08,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//awr 171 0x1A,0x00,0x24,0x00,0x00,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//awx 172 0x00,0x00,0x00,0x00,0x00,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x10,0x00,//awj 173 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aa 174 0x00,0x00,0x08,0x00,0x04,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aaf 175 0x00,0x00,0x02,0x00,0x04,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aas 176 0x00,0x00,0x00,0x00,0x06,0x00,0x32,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aar 177 0x1A,0x00,0x24,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x00,0x00,//aax 178 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0x1C,0x00,0x6C,0x00,0xCC,0x00,0xCC,0x00,0x7E,0x00,0x00,0x00,0x10,0x00,//aaj 179 0x00,0x00,0x00,0x00,0x00,0x00,0x06,0x00,0x0F,0x00,0x06,0x00,0x36,0x00,0x6E,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x6F,0x00,0x36,0x00,0x00,0x00,0x00,0x00,//dd 180 0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//ef 181 0x00,0x00,0x00,0x00,0x00,0x00,0x08,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//es 182 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x10,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//er 183 0x00,0x00,0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//ex 184 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x10,0x00,//ej 185 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//ee 186 0x10,0x00,0x08,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//eef 187 0x04,0x00,0x08,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//ees 188 0x18,0x00,0x08,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//eer 189 0x34,0x00,0x48,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x00,0x00,//eex 190 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x48,0x00,0x00,0x00,0x78,0x00,0xCC,0x00, 0xCC,0x00,0xFC,0x00,0xC0,0x00,0xC0,0x00,0xC4,0x00,0x78,0x00,0x00,0x00,0x10,0x00,//eej 191 0x80,0x00,0x40,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,//if 192 0x20,0x00,0x40,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,//is 193 0xC0,0x00,0x40,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,//ir 194 0x50,0x00,0xA0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,//ix 195 0x00,0x00,0x00,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,0xC0,0x00, 0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0xC0,0x00,0x00,0x00,0xC0,0x00,//ij 196 0x00,0x00,0x00,0x00,0x00,0x00,0x10,0x00,0x08,0x00,0x00,0x00,0x3E,0x00,0x63,0x00, 0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x3E,0x00,0x00,0x00,0x00,0x00,//of 197 0x00,0x00,0x00,0x00,0x00,0x00,0x04,0x00,0x08,0x00,0x00,0x00,0x3E,0x00,0x63,0x00, 0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x3E,0x00,0x00,0x00,0x00,0x00,//os 198 0x00,0x00,0x00,0x00,0x1C,0x00,0x04,0x00,0x08,0x00,0x00,0x00,0x3E,0x00,0x63,0x00, 0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x63,0x00,0x3E,0x00,0x00,0x00,0x00,0x00,//or 199 0x00,0x00,0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//ox 200 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x10,0x00,//oj 201 0x00,0x00,0x00,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//oo 202 0x10,0x00,0x08,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//oof 203 0x04,0x00,0x08,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//oos 204 0x18,0x00,0x08,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//oor 205 0x1A,0x00,0x24,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//oox 206 0x00,0x00,0x00,0x00,0x00,0x00,0x38,0x00,0x6C,0x00,0x00,0x00,0x7C,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x10,0x00,//ooj 207 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x02,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//ow 208 0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x12,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//owf 209 0x00,0x00,0x00,0x00,0x00,0x00,0x08,0x00,0x12,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//ows 210 0x00,0x00,0x00,0x00,0x00,0x00,0x18,0x00,0x0A,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//owr 211 0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x02,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x00,0x00,//owx 212 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x02,0x00,0x01,0x00,0x7D,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0x7C,0x00,0x00,0x00,0x10,0x00,//owj 213 0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x10,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uf 214 0x00,0x00,0x00,0x00,0x00,0x00,0x08,0x00,0x10,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//us 215 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x10,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//ur 216 0x00,0x00,0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//ux 217 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xC6,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x10,0x00,//uj 218 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x03,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uw 219 0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x13,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uwf 220 0x00,0x00,0x00,0x00,0x00,0x00,0x08,0x00,0x13,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uws 221 0x00,0x00,0x00,0x00,0x00,0x00,0x30,0x00,0x13,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uwr 222 0x00,0x00,0x00,0x00,0x34,0x00,0x48,0x00,0x03,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x00,0x00,//uwx 223 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x03,0x00,0x01,0x00,0xC7,0x00,0xC6,0x00, 0xC6,0x00,0xC6,0x00,0xC6,0x00,0xC6,0x00,0xCE,0x00,0x77,0x00,0x00,0x00,0x10,0x00,//uwj 224 0x00,0x00,0x00,0x00,0x00,0x00,0x10,0x00,0x08,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x20,0x00, //ỳ 0x00,0x00,0x00,0x00,0x00,0x00,0x04,0x00,0x08,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x20,0x00, //ý 0x00,0x00,0x00,0x00,0x0c,0x00,0x04,0x00,0x08,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x20,0x00, //ỷ 0x00,0x00,0x00,0x00,0x00,0x00,0x14,0x00,0x28,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x20,0x00, //ỹ 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xf7,0x00,0x62,0x00, 0x62,0x00,0x34,0x00,0x34,0x00,0x18,0x00,0x18,0x00,0x10,0x00,0x10,0x00,0x24,0x00, //ỵ //229 0x00,0x00,0x38,0x00,0x44,0x00,0x44,0x00,0x44,0x00,0x38,0x00,0x00,0x00,0x00,0x00, 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // ° do C //230 0x00,0x00,0x00,0x00,0x38,0x70,0x7c,0xf8,0xff,0xfc,0xff,0xfc,0xff,0xfc,0xff,0xfc, 0x7f,0xf8,0x3f,0xf0,0x1f,0xe0,0x0f,0xc0,0x07,0x80,0x03,0x00,0x00,0x00,0x00,0x00, // ❤ //trai tim 231 0x00,0x00,0x00,0x00,0x04,0x40,0x0c,0x20,0x1c,0x90,0xfc,0x48,0xfd,0x28,0xfc,0xa8, 0xfd,0x28,0xfc,0x48,0x1c,0x90,0x0c,0x20,0x04,0x40,0x00,0x00,0x00,0x00,0x00,0x00, // 🔊 speaker 232 0x07,0xc0,0x18,0x30,0x31,0x18,0x61,0x0c,0x61,0x0c,0xc1,0x06,0xc1,0x06,0xc1,0x06, 0xc1,0xf6,0xc0,0x06,0xc0,0x06,0x60,0x04,0x60,0x0c,0x30,0x18,0x18,0x30,0x07,0xc0, // 🕒 clock 233 0x01,0x00,0x41,0x08,0x21,0x10,0x10,0x20,0x03,0x80,0x07,0xc0,0x0f,0xe0,0xef,0xee, 0x0f,0xe0,0x07,0xc0,0x03,0xa0,0x10,0x10,0x21,0x08,0x41,0x04,0x01,0x00,0x00,0x00, // ☀ mặt trời 234 0x01,0x80,0x00,0xE0,0x00,0xF8,0x00,0xF8,0x00,0x7C,0x00,0x7E,0x00,0x7E,0x00,0x7E, 0x00,0xFE,0x00,0xFE,0x01,0xFE,0x03,0xFC,0x07,0xF8,0x3F,0xF8,0x7F,0xE0,0x1F,0x80, //🌙 mat trang 235 0x07,0x80,0x0F,0xE0,0x1F,0xF0,0x1F,0xFC,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF, 0x00,0x00,0x04,0x40,0x0C,0xC0,0x11,0x00,0x13,0x00,0x00,0x00,0x00,0x00,0x00,0x00, // ☁ mưa 236 0x18,0x1c,0x3c,0x3e,0x60,0x03,0xcf,0xf1,0x1c,0x1c,0x38,0x8c,0x30,0x86,0x60,0x86, 0xe0,0x83,0xe0,0xf3,0xe0,0x03,0x60,0x02,0x70,0x06,0x3c,0x1e,0x0f,0xf8,0x03,0xe0, //⏰ báo thức (Alarm) 237 0xff,0xff,0x80,0x01,0x80,0x01,0x88,0x71,0x98,0x89,0xa9,0x05,0x89,0x05,0x89,0x05, 0x89,0x05,0x89,0x05,0x89,0x05,0x88,0x89,0xbe,0x71,0x80,0x01,0x80,0x01,0xff,0xff, // 🔟 lich 238 0x00,0x1C,0x00,0x38,0x00,0x71,0x00,0x73,0x00,0x7F,0x00,0x7E,0x00,0xFC,0x01,0xE0, 0x03,0xC0,0x3F,0x80,0x7F,0x00,0xFE,0x00,0xDE,0x00,0x8E,0x00,0x0C,0x00,0x18,0x00, // 🔧 setup 239 }; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
const unsigned char size_font16[] = //bảng lưu kích cỡ chiều dài của font, ví dụ trữ m sẽ dài hơn chữ i { 0,12,12,12,12,12,12,12,12,12,13,12,12,12,12,12,12, 12,11,10,10,10,10,10,10,11,11,11,11,10,7,7,3, 7,8,0,9,10,10,4,6,6,7,0,4,7,4,7,9,7,9, 9,9,9,9,8,9,9,4,4,10,10,10,8,16,12,11, 11,11,10,10,12,12,7,10,12,10,15,13,12,10,12,12, 8,11,11,13,17,13,12,11,9,9,9,9,9,7,8,9, 7,9,7,7,9,9,3,5,10,7,15,10,8,8,8,7, 6,7,9,9,12,9,9,7,7,5,6,7,7,7,7,12, 12,12,12,12,12,12,12,12,13,12,13,13,13,13,13,13, 11,11,11,11,11,12,12,12,12,12,12,13,13,13,13,13, 8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8, 8,9,7,7,7,7,7,7,7,7,7,7,7,3,4,3, 5,3,9,9,9,8,8,8,8,8,8,8,8,9,9,9, 9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9, 9,9,9,7,15,14,16,16,16,17,17,17,17, }; |
Xây dựng chương trình vẽ font ra màn hình
Ta đã có Hàm Matrix_setpx có nhiệm vụ vẽ màu lên pixel x,y
|
1 2 3 4 5 6 7 |
unsigned char read_font16(int x, int y, int txt) { unsigned char temp = x % 8; unsigned char x1 = 0x80 >> temp; unsigned char x2 = 7-temp; return (font16[txt * 32 + y * 2 + x / 8] & x1) >> x2; } |
Hàm read_font16 có nhiệm vụ hỏi xem ở tọa độ x,y của font chữ có màu gì, ở đây màu là trắng hoặc đen tương ứng 0 hoặc 1
|
1 2 3 4 5 6 7 8 |
unsigned char c[2]={0,0}; void put_font16(int x,int y,int txt,unsigned char color) { c[1]=color; for(int i=0;i<size_font16[txt]-1;i++) for(int h=0;h<16;h++) setpx(i+x,h+y,c[read_font16(i,h,txt)]); } |
Hàm put_font16 để in ra 1 kí tự ở tọa độ x,y
|
1 2 3 4 5 6 7 8 9 10 11 12 |
void sendString_font16(int x,int y,unsigned char *s,unsigned char color) { unsigned char offset=0; unsigned utf8_addr; while(*s) { utf8_addr=UTF8_GetAddr(s,&offset); put_font16(x,y,utf8_addr,color); s+=offset; x += size_font16[utf8_addr]; } } |
Cuối cùng là hàm sendString_font16 để in 1 chuỗi văn bản UTF-8 ra màn hình
Và đây là thành quả của mình !



Kích hoạt chế độ gõ UTF-8 ở 1 số phần mềm lập trình
Arduino IDE được kích hoạt sẵn rồi, không cài gì thêm cả
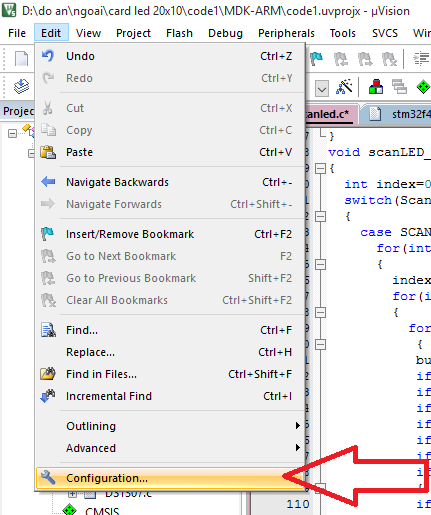
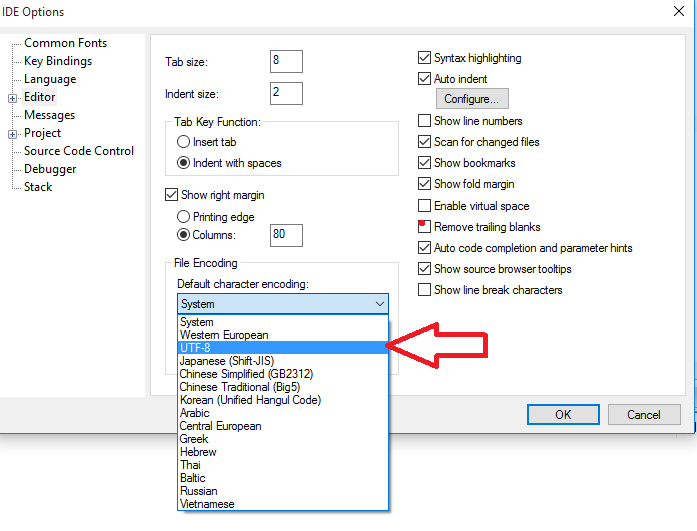
KeilC thì bạn vào config để bật UTF-8 encoding lên nhé:
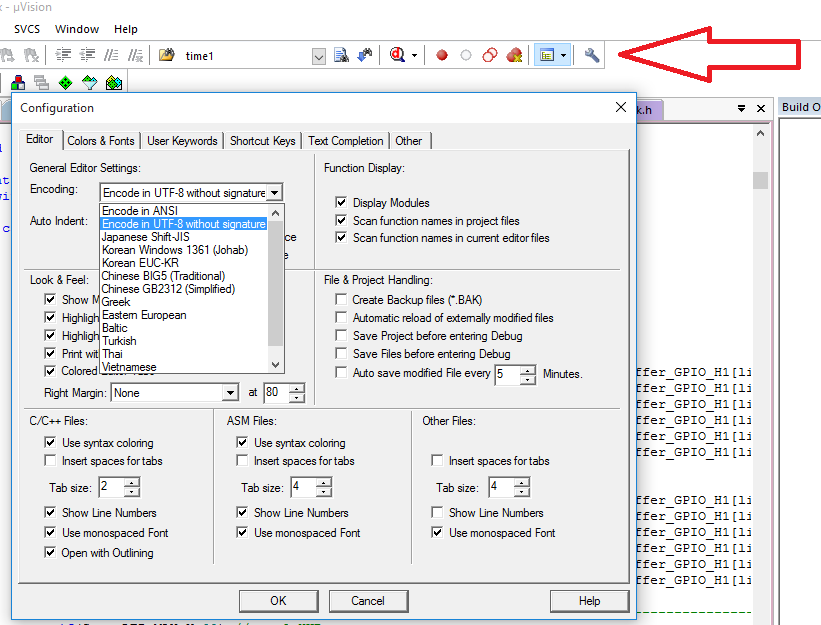
Nếu không thấy thì vào chỗ này
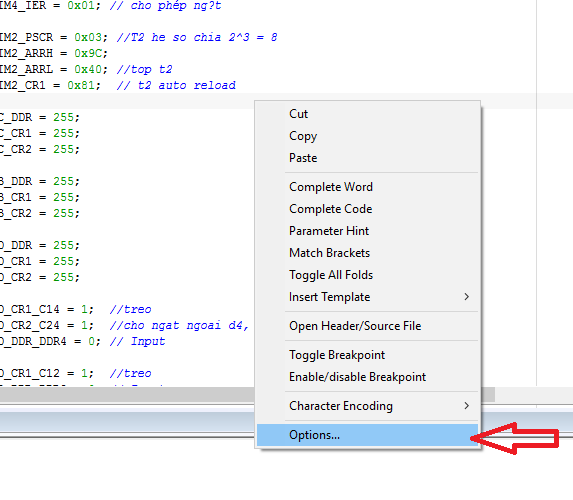
IAR cũng tương tự:
Cho anh xin bộ font đầy đủ được k em? Font ở trên mấy ký tự chữ thường có dấu k có dữ liệu. thank!
font chuẩn mà anh
thanks bạn nha, bài viết tuyệt vời. nhân tiện mình xin font16 của bạn nha
Chào Đào Nguyện, tôi có copy font UTF-8 của bạn gắn vào chương trình quét led ma trận của tôi sử dụng ESP8266 ra MAX7219 led ma trận để muốn hiển thị ngày tháng bắng tiếng việt, nhưng cài váo thì báo lỗi expected ‘,’ or ‘;’ before ‘unsigned’ khi biên dịch, vậy có cách nào giúp chú
đối với arduino IDE anh thử thêm PROGMEM vào mảng font xem
và anh phải dùng pgm_read_word để đọc dữ liệu trong font ra thì phải
pgm_read_byte cho kiểu uchar
keil c ko thể viêt chữ có dấu tiếng việt vào được, vd chữ â thì được nhưng chữ ă thì ko viết được, mà khi hiển thị trên led maxtrix nó chỉ có dấu ?, có cách khắc phục ko giúp chỉ với
cảm ơn nhiều
gõ trái tim búa, cà lê, âm thanh là gì vậy
copy paste vào là đc
size_font16 chiều dài font lấy bằng cách nào hoặc tính toán như thế nào vậy bạn